Abbildung 2: Proxy Anordnungen im Vergleich
Abbildung 2: Proxy Anordnungen im Vergleich
3.1 Hypertext Transfer Protocol
Derzeit aktuelles Protokoll von WWW Clients und Servern ist das Hypertext
Transfer Protocol in der Version 1.0 (HTTP/1.0)5. Aufbauend auf einer
TCP/IP6Verbindung bietet es die
Möglichkeitüber URL7 eindeutig
deklarierte Objekte im WWW zu adressieren und zu beziehen.
Die Möglichkeiten für Caching sind eingeschränkt. Erst mit der verbesserten abwärtskom-patiblen Version 1.1 wurden die offensichtlichsten Mängel von HTTP beseitigt. Im Kapitel 4.1 werden die Veränderungen im Zusammenhang mit Kohärenz-Mechanismen erklärt.
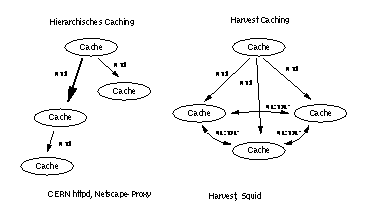
Um die Effizienz einfacher Caches zu steigern, haben sich hierarchische Strukturen mitCaches auf verschiedenen Ebenen entwickelt. Bei einer reinen Baumstruktur haben sich aber die Verbindungen zwischen den Servern weiter oben in der Wurzel als problematisch, weilleichtüberlastbar, erwiesen. Abbildung 2 zeigt die hierarchische Struktur im Vergleich zu der im nächsten Kapitel beschrieben Harvest Anordnung, die dieses Problem behoben hat.
Die Harvest-Software ist bis zur Version 1.4 frei erhältlich. Die aktuelle Version 2.0ist mit Support als kommerzielles Produkt zu beziehen. Als freie Weiterentwicklung des Harvest Caches gibt es den Squid beim National Laboratory for Applied Network Research. In Funktionalität und Stabilität entspricht er etwa dem kommerziellen Produkt.
Beide Proxy Caches - Harvest und Squid - unterstützen, anders als der Server vom W3C (CERN), nicht nur hierarchisches Caching, sondern auch eine komplexe Strukturierungüber Nachbarn und Eltern (vgl. Abbildung 2). So ist es einem Benutzer möglich, ein Dokument über den gesamten Cache-Verbund zu erhalten. Bei einem Cache-Miss9 werden zuerst die Nachbarn über ein optimiertes, auf UDP10 aufgesetztes Protokoll befragt, und nur wenn keiner erreichbar (Timeout) oder es nicht vorhanden ist, wird das Objektüber den ParentCache bezogen. Der Cache kann auch negativ cachen. Wenn ein Server kurzfristig tot ist, wird (auf Basis eines definierbaren Timeouts) nicht ständig Bandbreite verschwendet, um ihn zu erreichen [Sch96].
Derzeit baut der Verein zur Förderung eines Deutschen Forschungsnetzes e.V. (DFN-Verein) in einem vom Bundesministerium für Bildung, Wissenschaft, Forschung und Technologie (BMBF) geförderten Projekt einen nationalen Cache-Server-Verbund [Pra95].
Weitere Informationen hinsichtlich Einsatz und Funktionalität von Harvest Cache Softwa-re bietet [Fis97].
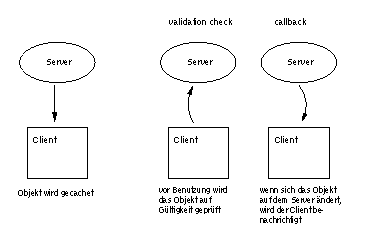
Abbildung 3: Kohärenz-Mechanismen: validation check vs. callback
3.2 Mirrors
Besonders aus dem Anonymous FTP11 Bereich ist die Technik der Replikation
entfernterServer bekannt. Sogenannte Mirrors oder Spiegelungen entfernter
FTP Server verringern internationale Netzlast. Um lokale Kopien der
gesuchten Objekte zu finden werden Servicewie Archie angeboten, die
über Indizes der einzelnen Server diese Objekte lokalisieren.
Einige Server verteilen die Benutzer auch selbst dynamisch auf den nächsten freien Knoten im Verbund. Dies funktioniert ebenfalls über vorher eingerichtete Indizes, die noch per Hand gepflegt werden können. Für den Einsatz im World Wide Web müsste dieser Ansatz vereinfacht und automatisiert werden. Ideen in diese Richtung werden im Kapitel 5.2 näherbetrachtet und auf ihre Leistungsfähigkeit getestet.
---------------------------------------------------------------- [home] [TOC] [prev] [next] [guestbook] [contact] (c) SM