Kohärenz-Mechanismen kann man in zwei generelle Klassen einteilen: validation check und callback Mechanismen. Die Abbildung 3 zeigt die zwei grundlegenden Techniken, mit der die Korrektheit und Aktualität eines gecacheten Objekts garantiert werden kann.
Die Grössenordnung des WWW bedingt, dass dort eigentlich nur die Kohärenzprüfung über validation check praktikabel ist. Eine einzelne Seite kann in Tausend oder Millionen Caches (jeder Web-Browser ist einer) gespeichert werden. Dies macht es für einen Server unmöglich, alle Caches zu benachrichtigen. Durch eine hierarchische Struktur könnte manzwar die Zahl der zu benachrichtigenden Caches verringern, aber es bleibt ineffektiv bei jeder Änderung irgendeiner Seite im WWW eine Notify-Lawine zu starten.
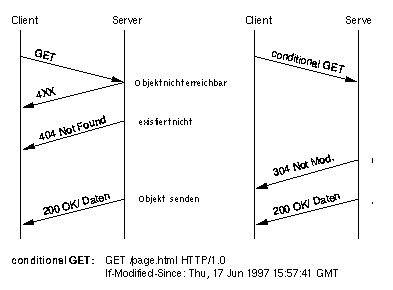
Naive Kohärenz-Mechanismen sind die am Beispiel heutiger Browser schon angesprochenen Check-Every-Time und Check-Never Mechanismen. Im ersten Fall wird immer, wenn ein GET oder conditional GET12 für eine gecachete Seite eingeht, ein conditional GET an den nächsthöheren Cache oder an den Server gesendet. Das conditional GET ergänzt das normale GET des HTTP/1.0 um ein Not Modified. Der Client erweitert die GET-Anfrage um eine If-Modified-Since Zeile mit dem Datum der im Cache gespeicherten Seite. Ist das Originaldokument unverändert, antwortet der Server mit einem 304 Not Modified und derClient zeigt die lokale Kopie an. Im anderen Fall sendet der Server ein 200 OK und die neue HTML-Seite. Der Check-Every-Time-Ansatz in Zusammenhang mit einem conditional GET war der erste eingesetzte Kohärenz-Mechanismus. Für den umfangreichen Einsatz im World Wide Web ist er allerdings wenig brauchbar. Wenn jeder Cache mit einem conditional GET an einenübergeordneten Cache bzw. an den Server selbst reagiert, wird jede Anfrage bis zum Server durchgereicht. Dies führt, selbst wenn keine HTML-Datenübertragen werden müssen, zuübermässiger Netzlast und reduziert die Anzahl der Anfragen an den Remote Server nicht.Der zweite naive Kohärenz-Mechanismus, der oben angesprochen wird: Never-Check, überprüft nie, ob die gecachete Seite noch aktuell ist. Um eine Seite explizit neu zu laden, muss der User einen Header mit Pragma:no-Cache-Zeile verwenden. Diese Technik verringert zwar die Netzlast, gibt aber keinerlei Garantie für die Aktualität desübertragen Dokuments. HTTP/1.113 ist die Weiterentwicklung des Hypertext Transfer Protocol 1.0 und bietet neben Fortschritten, wie Pipelining und Kompression, auch hinsichtlich des Cachings einige zusätzliche Möglichkeiten [Fie97]. Caching in HTTP/1.1 basiert auf zwei unterschiedlichen Ansätzen: dem Expiration- und dem Validation-Modell.
Entweder gibt ein Server für eine Seite explizit eine Verfallzeit an, oder der Proxy Cacheberechnet eine heuristische. Für den zweiten Fall gibt die HTTP/1.1-Spezifikation zwar keine Algorithmen, aber Rahmenvorgaben für ihr Ergebnis an. Alle Server sind aufgefordert, so oftwie möglich eine explizite Expiration-Zeit anzugeben, da die heuristischen Grenzzeiten nur mit Vorsicht zu betrachten sind [Fie97].
Weitere Überlegungen [DP96] betonen die Notwendigkeit, dem
Benutzer eine Art Gültigkeitsgarantie in Prozent zu bieten. Zu
jedem gesendeten Dokument sollte dem Benutzer zusätzlich das
Expiration-Datum oder die spekulative Berechnung des Caches offengelegt
werden. Wenn das so angezeigte Dokument nicht den Bedingungen des
Benutzers genügt,kann er explizit eine "bessere" Kopie aus einem
höheren Cache oder direkt vom Orginal-Server anfordern.
4.2 Effizienz
Die zweite Hauptforderung neben Kohärenz an Web Caches ist Effizienz.
Dies kann nur über eine hohe Treffer-Quote erreicht werden. Und da
derzeitige Caches nur einen relativbeschränkten Speicherraum
besitzen, besteht die Notwendigkeit,ältere Dokumente aus dem Speicher
zu löschen. Der von Festplatten und RAM-Caches bekannte, und dort
optimale Algorithmus Least Recently Used (LRU), ist beim Caching von WWW
Objekten nicht optimal [Abr95]. Im Folgenden wird ein kurzer
Überblicküber die Problematik gegeben und ein Vergleich
verschiedener denkbarer Ersetzungsstrategien versucht.
Web-Caches besitzen eine Obergrenze, die auf die Anforderungsrate aus statistischen Untersuchungen zurückzuführen ist, für die Hit-Rate von 30%-50% bei theoretisch unendlicher Cache-Grösse [Abr95]. Ziel der Ersetzungsstrategie ist es, diese theoretischen Werte auch beirealen, kleineren Cache-Speichern zu erreichen. [Abr95] vergleicht die drei LRU Varianten bei ihrem Verhalten Cache-Speicher zu befreien und kommt zu dem Ergebnis, dass der klas-sische LRU schlechter als LRU/MIN und LRU/THOLD abschneidet. Dies liegt daran, dass er unabhängig von der Grösse eines Objekts z.B. für ein grosses Video von einem Benutzerviele kleinere Dokumente im Cache ersetzt. Daraus resultieren Cache-Fehler für viele Benutzer. LRU-THOLD hält die Cache-Grösse relativ klein, nur ist es schwierig, die effektivste Threshold-Grenze zu finden. Das Ergebnis hinsichtlich der optimalen Ersetzungstrategie fälltbei [Abr95] folgendermassen aus: use LRU-MIN until the cache size approached 100% of the available disk size, and the switch to LRU-THOLD with a threshold that is gradually reduced, until the cache size reaches a low-water mark.
Ein weiteres Ergebnis ist die Empfehlung, nonpersistente Client-Caches zusammen miteinem gemeinsamen Proxy zu verwenden. Bei persistenten Caches der einzelnen Clients fällt die Trefferrate des Proxy Caches mit der Zeit, da sich die Caches der einzelnen Client füllen und nur noch Fehlanfragen dort an den Second-Level-Proxy-Cache weitergereicht werden. Mit einer besseren Nutzung des Proxy-Caches kann Speicherplatz gespart werden, und aufgrund der grösseren Anzahl der Zugriffe kann der Proxy Server besserüber das Caching einzelner Dokumente entscheiden [Abr95].
Im Vergleich zwischen LRU- und LFU-Strategien zeigt sich, dass für den Einsatz bei ProxyCaches die Anzahl der Zugriffe auf ein Dokument statt der Zeit seit dem letzten Zugriff das bessere Entscheidungskriterium ist [Wil96]. Deshalb verwendet der Algorithmus HYB auch diesen Faktor [WA97]. Die Ergebnisse aus [WA97] belegen ausserdem, dass eine Ersetzungsstrategie, die nur auf die geschätzte Download-Zeit des Objektes (LAT) aufbaut, nicht optimal ist. Die Trefferrateliegt deutlich unter der, die z.B. SIZE bei gleicher Versuchsumgebung ergibt [WA97].
Der ebenfalls in [WA97] geprüfte Algorithmus HYB ergibt sowohl bei Trefferrate als auch der Download-Zeit, auf verschiedenen Datenbasen die besten Ergebnisse. Wahrscheinlich ist der Ansatz, mehrere Faktoren in die Ersetzungsentscheidung miteinzubeziehen, sinnvoll und kann die durchschnittlichen Werte verbessern und stabilisieren.Ausserdem darf der psychologische Effekt der grossen Variation der Download-Zeit auf den Benutzer nicht ignoriert werden. Bei Strategien, die die Zeit berücksichtigen, variierendie Download-Zeiten weniger, und dem Benutzer fällt gleichmässig längeres kurzes Warten weniger auf, als langes Warten bei einzelnen Seiten [WA97].
Alle hier vorgestellten Ersetzungsstrategien haben gemeinsam, dass sie über Objektattribute, wie Zeit, Zugriffshäufigkeit, Grösse, etc. die Verweildauer im Cache berechnen. Der Inhaltwird nicht bewertet. Dass es hier auch andere Ansätze gibt, zeigt der Abschnitt 5.3. Dort wird ein besonders für Datenbanken interessanter Ansatz des semantischen Cachings beschrieben.
12) Die Abbildung 4 zeigt das Zusammenspiel von Client und Server bei einem klassischem GET und die Ergänzungen, die ein conditional GET bietet.
13) beschrieben in RFC 2068
---------------------------------------------------------------- [home] [TOC] [prev] [next] [guestbook] [contact] (c) SM