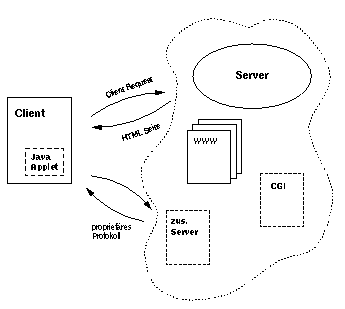
Abbildung 5: Derzeitübliche Konfiguartion eines HTTP-Server
Das Common Gateway Interface (CGI) ermöglicht dem Server beliebige Inhalt on demand zu erzeugen. Jeder Aufruf führt auf Serverseite zur Abarbeitung eines Programms, das dy-namisch den Inhalt der WWW Seite erzeugt. So wird derzeit noch häufig eine propritäre Anbindung von Datenbanken ans WWW implementiert. Die relativ beschränkten Möglichkeiten und die Zunahme der Last auf Serverseite hat einen weiteren Entwicklungsstand gefördert. Durch Erweiterung der Browser um die Möglichkeit Java-Applets Client-seitig ausführen zu können, kann so -- immer noch proprietär -- die Funktionalität erweitert werden.
Dieser bietet aber weder standardisierte Kommunikationsprotokolle, noch wird so eineCaching-Struktur unterstützt. Dies soll HTTP-NG zusammen mit der gewünschten Funktionalität unterstützen (vgl. Abbildung 5).
Abbildung 5: Derzeitübliche Konfiguartion eines HTTP-Server
Eine andere Entwicklungsrichtung die Alternativen zum derzeitigen
HTTP-Standard bietet ist das Internet Inter-ORB15-Protocol (IIOP)
(vgl. Abbildung 6). Der WWW Server befindet sich auf einem
Rechner, auf dem ausserdem ein CORBA16 -Server läuft. CORBA als
langjähriger offener Standard bietet gute Voraussetzungen, mit denen
IIOP die derzeitige Mischung aus HTTP und proprietären Lösungen
ersetzen und vereinheitlichen kann [Mer97].
5.2 Replikationen, Preloading
Ein weiterer vielversprechender Trend [Ber95] ist die Weiterentwicklung der
Spiegelung häufig benutzter Server in die Nähe der Benutzer.
Schon heute werden viele populäre Web Server (z.B. Alta Vista,
Netscape) weltweit repliziert. Dies ist eine Möglichkeit, erfolgreich
mit der wachsenden Anzahl an Zugriffen auf Serverseite umzugehen. Nur muss
der Anwender zur Zeit wissen und explizit angeben, welche Replikation er
benutzen soll. Dies kann nichtdie Lösung für die zunehmende
Anzahl der Benutzer sein, die die Technik des Internets nur anwenden, nicht
aber verstehen wollen. Hier müsste ein Mechanismus gefunden werden,
der automatisch die "nächstgelegene", verfügbare Kopie liefert.
Möglichkeiten, die auf NNTP17 oder Multicast-Verbindungen aufbauen, sind
hier vorstellbar [Ber95].
Statt neuer Technologie geht ein anderer Vorschlag davon aus, dass es besser ist, innerhalb des bestehenden und auszubauenden Cache-Verbundes Replikation zu unterstützen [DP96]. Wenn ein Dokument eines Caches der Ebene n von vielen Caches der Ebene n-1 angefordertwird, sendet er das populäre Objekt an alle n-1-Caches. Die Abbildung 7 verdeutlicht diesen Mechanismus: Das xy-Objekt wird von vielen (hier zwei von fünf) Caches angefordert, dern-Level-Cache beantwortet die Anfrage normal mit einem OK und den Daten von xy. Doch zusätzlich sendet er das "heisse" Objekt auch an die restlichen (drei) Caches. Dieses Vorgehen ermöglicht es, sozusagen innerhalb der Web Caches Replikationen häufig frequentierter Server nahe bei den Benutzern zu erzeugen, ohne die oben angesprochenen Nachteile und noch zu klärenden Fragen.
Bei Preloading oder Prefetching, einer möglichen Erweiterung des Kohärenz-Mechanismus, prüft der Cache regelmässig, ohne direkte Anfrage eines Clients, selbständig die Aktualität "interessanter" Objekte im Speicher. In wie weit dies sinnvoll ist und welche Algorithmen gute Ergebnisse liefern, muss noch geprüft werden [DP96].
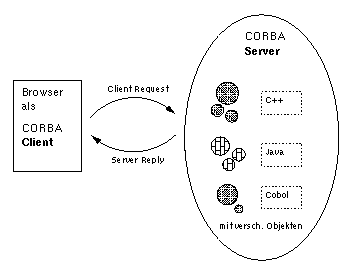
Abbildung 6: Server und Client beim Internet Inter-ORB Protocol (IIOP)
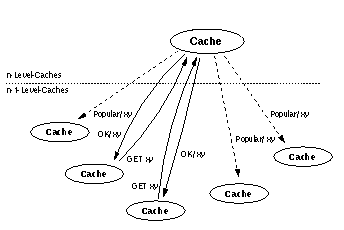
Abbildung 7: Replikation durch Web Caches
5.3 Semantisches Caching von Datenbankzugriffen im WWW
Wie in Abschnitt 4.2 schon angedeutet, sind die
dort beschriebenen Ersetzungsstrategien für das Caching von Ausgaben
relationaler Datenbanken nicht optimal. Beim assoziativen Zugriffauf eine
Datenbank werden Datenobjekte nicht direkt spezifiziert sondern
dynamischüber ihren Datenwert ausgewählt und in Tupeln
gruppiert. Deshalb ist der auf Objekte ausgelegte Ansatz heutiger
Caches nicht geeignet.
Eine andere Strukturierung für Caches stellt [Dar96] vor. Es werden nicht Objekte, sondern semantische Regionen im Speicher abgelegt. Jede semantische Region besitzt eine Formel von Bedingungen, die die Tupel in ihr beschreibt. Bei weiteren Anfragen an das Datenbanksystem wird die Anfrage in zwei disjunkte Teile zerlegt. Ein Teil wird mit den Daten im Cache beantwortet, und der zweite betrifft fehlende Tupel und wird an die Datenbank selbst gestellt.
Semantische Regionen lassen sich in kleinere Teilgruppen zerlegen oder zu grösseren verschmelzen. Ersetzungsentscheidungen werden so immer über die gesamte semantische Region getroffen [Dar96].
Unterstützt wird diese Technik derzeit noch von keinem Web-Cache, und selbst im reinen Datenbankumfeld wird sie nur in geringem Umfang eingesetzt. Dies liegt hauptsächlicham noch erforderlichen Forschungseinsatz. Viele Fragen sind noch nicht oder nur teilweise geklärt.
14) next Generation
15) Object Request Broker
16) Common Object Request Broker Architecture
17) Network News Transfer Protocol, beschrieben in RFC 977
---------------------------------------------------------------- [home] [TOC] [prev] [next] [guestbook] [contact] (c) SM