|
| Abbildung 3.1: Abstrakte Ebenen bei Java |
Die Benchmark Sammlung (Anhang A) beinhaltet mathematische Problemstellungen, wie das Primzahlensieb des Erathostenes oder die Multiplikation von Matrizen und Polynomen. Die Performance des Benutzerinterfaces oder auch die grafische Leistungsfähigkeit werden nicht betrachtet. Hier hängen bessere Testergebnisse meist mehr vom zugrundeliegenden System als von der JVM-Implementierung ab. X-Window und andere Client/Server-Grafik-Subsystemen geben anders, wie zum Beispiel die Grafikoberfläche von Windows 95, schon vor der kompletten Anzeige grafischer Elemente die Kontrolle an das Programm zurück. Dies verhindert eine genaue Zeitmessung und auch der Vergleich dieser beiden grundlegend verschiedenen Systeme ist schwer möglich.
Bei den einzelnen Benchmarks wurde Wert darauf gelegt, unterschiedliche Programmiertechniken (Rekursion, große Arrays, etc.) zu verwenden.
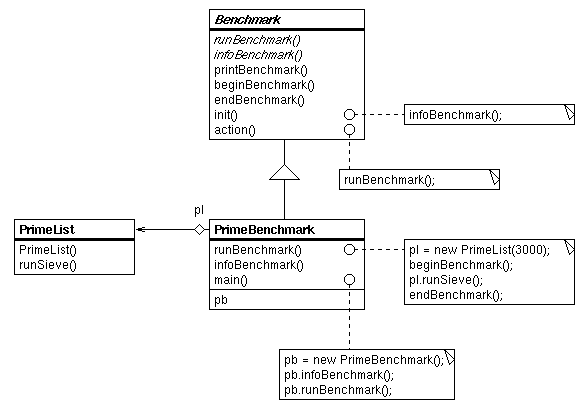 |
| Abbildung 3.2: OMT-Diagramm: PrimeBenchmark |
Das Diagramm1 in Abbildung 3.2 zeigt beispielhaft am Primzahlen-Benchmark (PrimeBenchmark) die objektorientierte Struktur der Benchmark-Klassen.
Benchmarkist eine abstrakte Klasse, von der alle konkreten Testprogramme erben. Sie stellt Methoden zur systemunabhängigen Ausgabe und Zeitmessung zur Verfügung. printBenchmark() leitet die Ausgabedaten bei einem Applet in ein Textfeld (java.awt.TextArea), bei einer Applikation an die Standardausgabe um. Die beiden Methoden beginBenchmark() und endBenchmark() sind eine Zeitklammer um den Benchmark, stoppen Start- und Endzeit, und geben die Laufzeit aus.
Die abstrakt definierten Routinen runBenchmark() und infoBenchmark() müssen von jedem Benchmark selbst implementiert werden. infoBenchmark() gibt den Name und die Versionsnummer des Tests aus, und in runBenchmark() wird der Test ausgeführt.
cij= SUMk=1n aik*bkj
und den Gauß -Algorithmus zum Lösen von Linearen Gleichungssystemen (LGS):
A(n,n)x=b
Der Algorithmus für die Multiplikation berechnet durch einfaches Aufsummieren in drei verschachtelten Schleifen die Lösungsmatrix. Bei einer quadratischen (n,n)-Matrix bedeutet dies einen Aufwand von O(n3). Für den Benchmark wird ein Produkt zweier (200,200)-Matrizen, mit zufällig gesetzten double-Werten, berechnet.
Das LGS wird mit dem Gaußschen Eliminationsverfahren, wie es beispielsweise in [Sedg91.1] beschrieben wird, gelöst. Der Test führt dies für ein Gleichungssystem mit 400 Gleichungen und 400 Unbekannten - in double - durch.
Der Primzahlentest ist zweigeteilt, einmal wird die Zeit zur Erzeugung des PrimeList-Objekts, das im wesentlichen ein boolean-Array der Länge 9.000.000 ist, gemessen und zum zweiten die Ausführungszeit des eigentlichen Primzahlensieb-Algorithmus.
Inhalt des Tests ist einmal der häufige Zugriff auf die 1000 Array-Elemente während des Sortiervorgangs und zweitens die 1000fache Wiederholung dieses Vorgangs.
public final Poly mult(Poly b) { /* */ }
aus der Klasse Matrix. privateund static Methoden sind implizit final.
Um Inkonsistenzen in der Zeitmessung zu vermeiden wird in den Benchmarks System.gc() verwendet. Dies veranlaßt den Java Interpreter die Garbage Collection gleichzeitig, und nicht nur bei Speicher-Bedarf, durchzuführen.
Um den zusätzlichen Aufwand der Garbage Collection zu vermeiden, kann es sinnvoll sein, häufig erzeugte und verworfene Objekte mit einer eigenen Speicherverwaltung zu versehen. Der Programmierer kann bei Freigabe die Objekte in eine Freiliste aufnehmen, und wenn ein Objekt entsprechender Größe neu angefordert wird, kann so die Erzeugungszeit gespart werden.
In der JVM-Spezifikation ist nicht festgelegt, welchen Algorithmus die Garbage Collection verwendet. Einen ersten Überblick der verschiedenen Techniken bietet der Onlineartikel Java's garbage-collected heap [Venn96].
Der langsame Zugriff auf Felder in Java kann bei zweidimensionalen Feldern dadurch abgeschwächt werden, daß eine zusätzliche eindimensionale Referenz eingeführt wird. Im folgenden Programmbeispiel aus MatrixBenchmark werden die variablen elem_i, elem_max, elem_j statt elem[i], elem[max] und elem[j] immer genau dann verwendet, wenn in einer Zeile der Matrix mehrere Elemente angesprochen werden.
public final void eleminate() {
double[] elem_i, elem_max, elem_j;
double dummy;
int i, j, k, max;
for (i = 0; i < rows; i++) {
max = i;
for (j = i+1; j < rows; j++)
if (Math.abs(elem[j][i]) >
Math.abs(elem[max][i])) max = j;
elem_i = elem[i];
elem_max = elem[max];
for (k = i; k > cols; k++) {
dummy = elem_i[k];
elem_i[k] = elem_max[k];
elem_max[k] = dummy;
}
for (j = i+1; j < rows; j++) {
elem_j = elem[j];
for (k = cols-1; k >= i; k--)
elem_j[k] -= elem_i[k] *
elem_j[i] / elem_i[i];
}
}
}
Zweidimensionale Felder werden in Java wie eindimesionale Felder von Feld-Objekten behandelt. Jeder Zugriff elem[i][k] bedeutet also, daß erst die Referenz auf a[i] mit einem getfield-Befehl der JVM (vgl. [Sun95b]) auf den Stack geholt wird, und anschließend mit dieser Adresse und einem weiteren getfield der Wert der Zelle. Durch Einführen einer zusätzlichen Referenz elem_i wird dies umgangen.
Es wird bei jeder Referenz ein iload- und ein aaload-Befehl im Java-Bytecode eingespart (http://www.cs.cmu.edu/~jch/java/compilers.html).
ähnliche Code-Verbesserungen, wie sie in vielen Hochsprachen üblich sind (die Entfernung von invarianten Ausdrücken in Schleifen, die Vorausberechnung von Abbruchbedingungen (rows statt elem.length) oder die Verwendung der x += y Operation statt x = x + y) wurden ebenfalls beachtet. Bei einfachen Integer-Variablen optimiert zwar auch der Compiler der JDK (javac, mit Parameter -O), aber spätestens bei Array-Zugriffen wie elem_j[k] = elem_j[k] - y geschieht dies nicht mehr. So verbesserter Code ermöglicht auch JITC weitergehende Optimierungen.
Poly al = new Poly(len2);
Poly bl = new Poly(len2);
try {
System.arraycopy(elem, 0, al.elem, 0, len2);
System.arraycopy(b.elem, 0, bl.elem, 0, len2);
}
catch(ArrayIndexOutOfBoundsException e) { }
catch(ArrayStoreException e) { }
statt einer einfachen Schleife:
for (int i = 0; i < len2; i++) {
al.elem[i] = elem[i];
bl.elem[i] = b.elem[i];
}
kann so Ausführungszeit in kritischen Bereichen eingespart werden.
Als Referenz-JVM ist auf jeder der Plattformen die JDK 1.0.2 von JavaSoft (bzw. bei Linux der Port von Randy Chapman) installiert. Deren Ergebnisse werden mit 100.0% gewertet, und abhängig davon der Prozentwert der anderen Interpreter/JIT-Übersetzer3 berechnet. So ist ein plattformübergreifer Vergleich an Relativwerten möglich.
Die Tests sind so dimensioniert, daß die Ausführungszeit mit dem Interpreter der JDK 1.0.2 zwischen einer und drei Minuten liegt.
 |
| Abbildung 3.3: Berechnungsbeispiel der Ergebnisse |
Neben Windows NT war Solaris (Abbildung 3.4) die erste Plattformen, für die Sun seine Referenzimplementierung einer JVM, die JDK, angeboten hat. Getestet wurden zwei verschiedene Versionen, die normale Distribution und eine spätere Version: dp11/13/96-15:42. Außer bei den Benchmarks mit Matrix- und Polynommultiplikation (105%) bringt diese bessere Ergebnisse. Die verschiedene Versionen der JDK 1.0.2 ergeben sich aus verschieden Freigabeterminen bei Sun/Javasoft. Mit neuen Entwicklungen wie dem Browser HotJava oder dem Java-Workshops , einer grafischen Entwicklungsumgebung für Java-Programme, ist auch immer die entsprechend aktuellste Version des Interpreters erhältlich. Insbesondere Fehler früherer Versionen sind dort behoben.
Kaffe ist eine frei erhältliche JVM, die für mehr als 20 Hardware/Betriebssystem-Varianten erhältlich ist. Sie ist eine sogenannte Clean-Room-Implementierung, d.h. sie baut nicht auf den Code von Sun Microsystems auf. Auf der Intel Plattform und - seit der hier getesteten Version 0.7.0 - auch auf SPARC unterstützt sie eine Just in Time-Übersetzung in maschinenabhängigen Code. Und obwohl sie immern\nobreak och ALPHA-Software ist, ist sie schon relativ stabil und sicher. Kaffe beinhaltet keine AWT, d.h. es wird keine Native-Library für das Abtract Window Toolkit mitentwickelt. Für Unix/X ist es aber möglich die in Abschnitt 5.1.4 beschriebenen AWT-Implementierungen einzubinden.
Im Test zeigt kaffe 0.7.0 (ausgenommen von PolyBenchmark) eine Laufzeitverbesserung von im Schnitt Faktor 5. Bei Aufgaben wie dem Primzahlensieb oder dem mehrfachen Sortiern der Integerliste ist die Steigerungen deutlicher. Das Lösen der Gaußelimination gelingt immerhin noch in 35.8% der Zeit, die der reine Interpretierer von Sun Microsystems benötigt. Negativ fällt nur der Test mit der Polynommultiplikation auf, mit 235.3% ist kaffe hier mehr als doppelt so langsam. Gründe hierfür werden im nächsten Abschnitt bei den JIT-Compilern für Windows gesucht.
Der Netscape Navigator 3.01 ist unter Solaris neben dem HotJava von Sun, der einzige WWW-Browser, der eine Java-Unterstützung bietet. Da HotJava direkt auf die JDK aufsetzt wurde auf einen Test verzichtet. Der Browser von Netscape unterstützt auf den Unix-Plattformen keine JIT-Compilierung, deshalb sind seine Ergebnisse bei den Benchmarks auch nicht weiter verwunderlich. Nur der Polynomtest und das Erzeugen des Primzahlenobjekts ergaben Abweichungen nach oben von bis zu 30 Prozentpunkten. Die restlichen Werte lagen zwischen 101.0% und 117.0%.
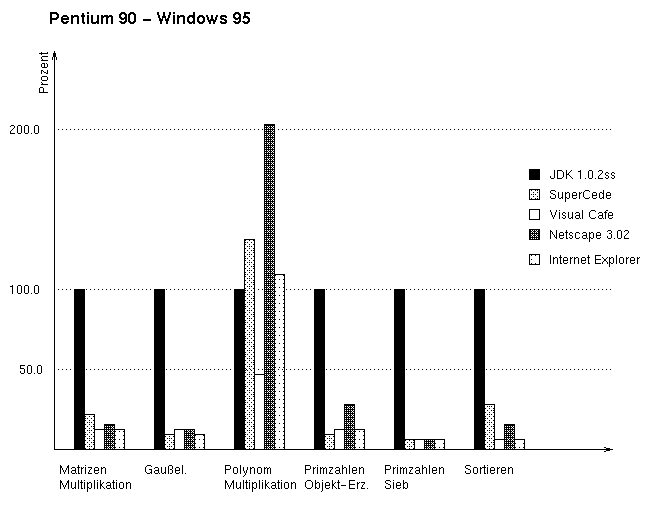 |
Besonders für Windows4 bieten viele Softwarehersteller JIT-Compiler (JITC) an. Bis auf die JDK 1.0.2 besitzen alle unter Windows getestete JVM diese Option. Im Überblick (vgl. Abbildung 3.5) bestätigen dies auch die Zahlen der Benchmarks. Bis zu Faktor 20 kann hier der Unterschied betragen (Primzahlensieb). Bei der Lösung des Gleichungssystems mit 400 Unbekannten und 400 Gleichungen liegen die vier JITC-Ergebnisse alle in einem Bereich von 10.2-12.4% des JDK-Wertes. Diese gleichen Leistungswerte sind aber keineswegs üblich, nur bei Berechnung des Primzahlensiebs haben die Werte eine ähnlich kleine Streuung (5.2-7.7%).
Grundsätzlich liegt die Ausführzeit der JVM im Netscape Browser in einer Größenordnung von 0.5 bis 1 über denen des Browsers von Microsoft (Internet Explorer). Auch die beiden Stand-alone-Produkte von Asymetrix und Symantec zeigen deutliche Unterschiede. Bei Matrizenmultipikation, Polynommultiplikation und im Sortieren der Integerliste übertrifft Visual Cafe PreBeta II SuperCede von Asymetrix in einem Faktor zwischen 1.8 und 4.2. Bei den Benchmarks mit Gaußelimination, Erzeugen des Objekts für den Primzahlentest und dem Primzahlensieb-Algorithmus selbst sind die Zeitwerte von SuperCede besser. Bei Prozentwerten von 5 bis 10 liegen die Abweichungen hier aber nur bei 2 bis 3 Prozentpunkten.
Auffallend aber sind besonders die Ergebnisse des Benchmarks mit der Multiplikation zweier Polynome der Länge 4000. Der Netscape Navigator hat hier eine doppelt so langen Ausführungszeit (203.7%) wie das Referenzsystem, die JDK von Sun Microsystems. Auch die anderen JITC ergeben hier keine ähnlichen Geschwindigkeitsverbesserungen wie bei den anderen Tests. SuperCede ist mit einem Wert von 130.2% langsamer, genau wie der Internet Explorer (IE) mit 108.1% und nur Symantec Visual Cafe ist mit 46.2% schneller als der reine Interpretierer, der JDK.
PolyBenchmark implementiert wie in Abschnitt 3.2 beschrieben eine rekursive Polynommultiplikation, in der das Problem in drei Teilprobleme der halben Größe geteilt wird und danach die Ergebnisse wieder zusammengesetzt werden. Hierfür werden in jedem Rekursionsschritt sechs neue Poly-Objekte erzeugt.
Dies stellt sich für die JITC als großes Problem dar. Um zu entscheiden, welche Programmteile die Beschleunigung durch die Just in Time-Compiler behindern, wird der Test in zwei aufgeteilt: InitBenchmark und RecBenchmark.
| JDK 1.0.2 ss08/12/96 | Super- Cede 1.0b | Visual Cafe 2.00b07 | Netscape 3.01 | IExplorer 3.02 | |
|---|---|---|---|---|---|
| Erzeugen von | (52.68) | (158.41) | 51.57 | (72.78) | |
| Objekten | (52.89) | 151.65 | (51.63) | länger | 72.12 |
| 52.73 | 145.06 | (51.36) | als | 71.96 | |
| 52.73 | (144.84) | 51.61 | 8 Min. | (71.30) | |
| 52.73 | 148.36 | 51.59 | 72.04 | ||
| 100.0% | 281.3% | 97.8% | 136.6% | ||
| Rekursiver | 12.25 | 1.37 | 0.88 | 0.94 | 0.99 |
| Abstieg | 100.0% | 11.2% | 7.2% | 7.7% | 8.1% |
Die Ergebnisse von InitBenchmark und RecBenchmark (vgl. für den Programmcode Anhang A) in Tabelle 3.1 zeigen, daß SuperCede, der Netscape Navigator und der Internet Explorer signifikant mehr Zeit bei der Erzeugung von neuen Objekten brauchen, als die JVM von JavaSoft. Daß die schlechten Resultate bei PolyBenchmark nicht von der Rekursion im Teile-und-Herrsche-Algorithmus abhängt zeigt auch RecBenchmark, ein Test, der eine einfachen rekursiven Abstieg in einem Objekt beinhaltet (vgl. Tabelle 3.1). Der Großteil der Ausführungszeit wird deshalb für das Erzeugen der Objekte aufgewendet.
Bei InitBenchmark braucht SuperCede ca. 2,8 mal länger (281.3%) als der Interpretierer der JDK von JavaSoft. Der nicht ebenfalls so schlechte Wert bei PolyBenchmark resultiert deshalb aus der guten Optimierung der restlichen Programmteile.
Visual Cafe von Symantec ist in der Lage, bei InitBenchmark die Zeit der JDK zu erreichen und knapp zu unterbieten. Auch hier wird der Zeitvorteil in PolyBenchmark durch Optimierung der anderen Programmkonstrukte erreicht.
Für die Programmentwicklung hat dies konkrete Folgen: Um nicht Performanceeinbußen hinnehmen zu müssen, ist das allzu häufige Erzeugen von Objekten zu vermeiden. In PolyBenchmark könnte dies zum Beispiel mit der Einführung einer Freiliste für nicht mehr verwendete Poly-Objekte und deren Recycling bei nächster Gelegenheit erreicht werden. Da die Rekursion einen Tiefensuchebaum erzeugt, d.h. einen Teilzweig immer erst bis zum letzten Blatt abarbeitet, könnten die auf diesem Weg erzeugten Objekte im nächsten Teilzweig wiederverwendet werden. Damit wird die Zeit zur Erzeugung eingespart.
Ein positiver Nebeneffekt wäre die Umgehung der Garbage Collection von Java. Laut Berichten in Newsgroups (de.comp.lang.java und comp.lang.java.*) und verschiedener Benchmarks ist sie bei den meisten Interpretern und JIT-Übersetzern nur schlecht implementiert.
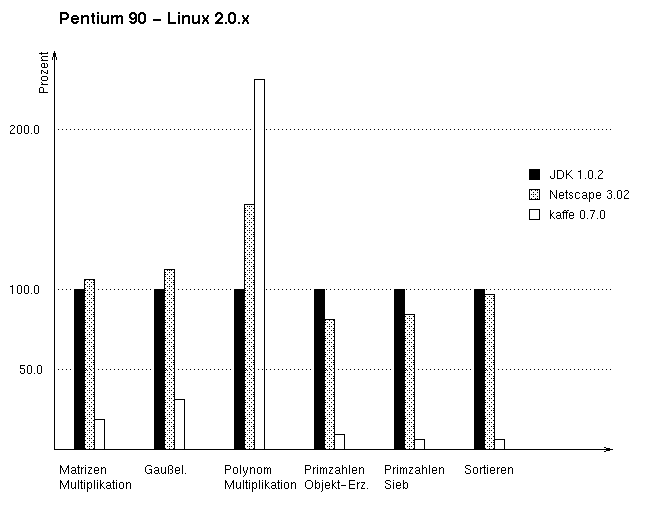 |
| Abbildung 3.6: Ergebnisse Pentium 90 - Linux, alle Benchmarks |
Die Ergebnisse des Netscape Navigators sind mit denen der anderen Unix-Plattform vergleichbar. Die Primzahlentests sind mit Prozentwerten von 81.2% und 83.2% besser als die Werte des Interpreters von JavaSoft; die Multiplikation der Polynome braucht 154.5% der Ausführungszeit der JDK.
Auch kaffe ergibt fast die gleichen Werte wie bei der SPARC-Version. Da die JITC-Option hier schon länger eingebaut und getestet ist unterstreicht das die Leistung bei der Solaris-Version, die erst mit der Version 0.7.0 eine Just in Time-Compilierung ermöglicht.
Das Erzeugen des großen Arrays für das Primzahlensieb ist unter Linux genau wie der Primzahlensieb-Algorithmus selbst und SortBenchmark relativ zur JDK doppelt so schnell wie unter Solaris. Ebenfalls negativ fiel PolyBenchmark auf. Die Werte lagen über dem Doppeltem der Sun-Ergebnisse. Wärend der Testläufe wurde eine Ausführung mit einer java.lang.NullPointerException beendet. Dieser Fehler ließ sich nicht wiederholen und deutet auf einen internen Fehler der kaffe JVM hin.
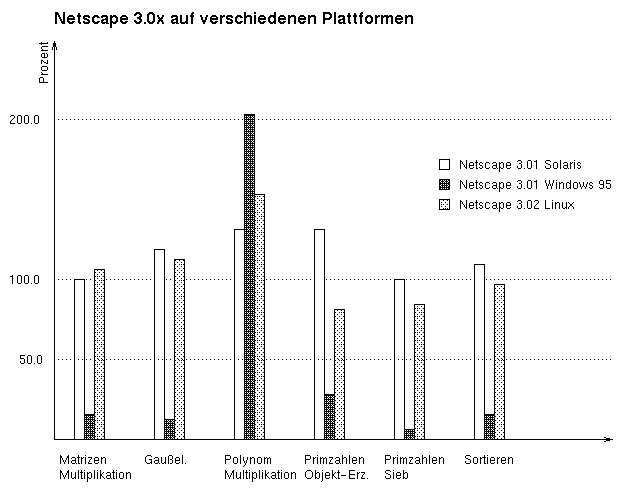 |
| Abbildung 3.7: Ergebnisse mit Netscape auf allen Plattformen, alle Benchmarks |
Natürlich unterscheiden sich auch die Leistungswerte der JDK selbst.
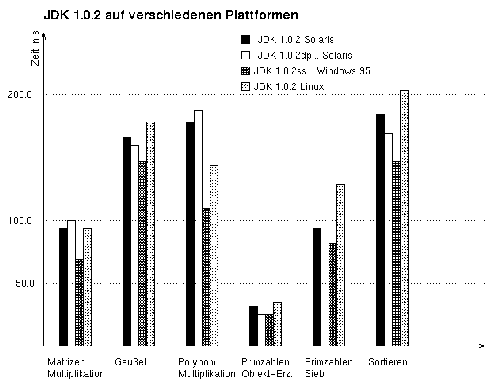 |
| Abbildung 3.8: Ergebnisse mit JDK 1.0.2 auf allen Plattformen, alle Benchmarks |
Hier schneidet die Windows-Version um durchschnittlich 30% besser ab (vgl. Abbildung 3.8).
Der CoffeinMark 2.5 besteht aus 9 Tests die alle Bereiche der Java-Programmierung abdecken. Zusätzlich zu numerischen Berechnungen, wie sie Grundlage der Benchmarks dieser Studienarbeit sind, werden auch Performace-Aspekte der Grafik und Zeichenkettenverarbeitung beachtet. Der CoffeineMark ist ein Mittelwert aus den 9 Test-Ergebnissen und gibt relativ zu einem Referenzsystem (mit Cyrix 6x86 P150+, Windows 95 und dem Symantec Cafe appletviewer im Debug-Modus) einen Leistungswert für die getestete JVM.
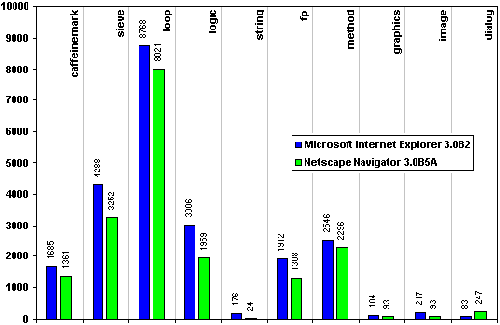 |
| Abbildung 3.9: Ergebnisse von CaffeineMark 2.5: JVM ohne JITC |
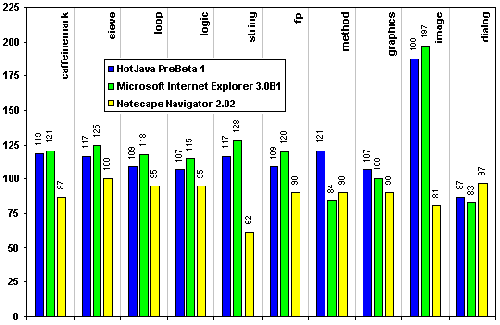 |
| Abbildung 3.10: Ergebnisse von CaffeineMark 2.5: JITC |
Die Abbildung 3.9 zeigt die Ergebnisse für HotJava PreBeta 1, Internet Explorer 3.0B1 und Navigator 2.02. Diese Browser-Versionen verfügen noch nicht über eine JIT-Compilierung.
Im Vergleich dazu zeigen die beiden Browser Internet Explorer 3.0B2 und Navigator 3.0B5A in Abbildung 3.10 deutliche Steigerungen der Ausführungsgeschwindigkeit. Besonders "sieve, loop, logic floating-point (fp) und der method Test", so Pendragon, "werden dramatisch bescheunigt". Dies kommt besonders "berechnungsintensive Animationen und 3D-Modellierung" (Pendragon) zugute.
1) Die Klassendiagramme in dieser Studienarbeit basieren auf OMT, der
Object Modeling Technique, wie sie in Auszügen in [GAMM96] beschrieben
wird.
2) Teil des Java Workshops für Windows von Sun Microsystems
3) Das Konzept der Just in Time-Compiler wird in Abschnitt 4.2 näher beschreiben.
4) Die Tests wurden unter Microsoft Windows 95 vorgenommen, da mit Microsoft
Windows NT nur ein 486/33 zur Verfügung stand und besonders bei den
JIT-Compilern die Leistung der Hardware wichtig wird. So ist auch
ein besserer Vergleich mit den Ergebnissen unter Linux auf der gleichen
Hardware möglich.
5) Battle of Browsers: http://www.webfayre.com/battle.html
---------------------------------------------------------------- [home] [TOC] [prev] [next] [guestbook] [contact] (c) SM